Learning to Schedule Heuristics in Branch and Bound
TL;DR: This is an informal discussion of our recent paper Learning to Schedule Heuristics in Branch and Bound by Antonia Chmiela, Elias Khalil, Ambros Gleixner, Andrea Lodi, and Sebastian Pokutta. In this paper, we propose the first data-driven framework for scheduling heuristics in a MIP solver. By learning from data describing the performance of primal heuristics, we obtain a problem-specific schedule of heuristics that collectively find many solutions at minimal cost. We provide a formal description of the problem and propose an efficient algorithm for computing such a schedule.
Written by Antonia Chmiela.
Motivation
Primal heuristics play a crucial role in exact solvers for Mixed Integer Programming (MIP). For instance, Berthold [1] showed that the primal bound improved on average by around 80% when primal heuristics were used. While solvers are guaranteed to find optimal solutions given sufficient time, real-world applications typically require finding good solutions early on in the search to enable fast decision-making. Even though much of MIP research focuses on designing effective heuristics, the question of how to manage multiple MIP heuristics in a solver has not received equal attention.
Generally, a solver has a variety of primal heuristics implemented, where each class exploits a different idea to find good solutions. During Branch and Bound (B&B), these heuristics are executed successively at each node of the search tree, and improved solutions are reported back to the solver if found. Since most heuristics can be very costly, it is necessary to be strategic about the order in which the heuristics are executed and the number of iterations allocated to each, with the ultimate goal of obtaining good primal performance overall. Such decisions are often made by following hard-coded rules derived from testing on broad benchmark test sets. While these static settings yield good performance on average, their performance can be far from optimal when considering specific families of instances.
In this paper, we propose a data-driven approach to systematically improve the use of primal heuristics in B&B. By learning from data about the duration and success of every heuristic call for a set of training instances, we construct a schedule of heuristics deciding when and for how long a certain heuristic should be executed to obtain good primal solutions early on. As a result, we are able to significantly improve the use of primal heuristics.
Contributions
Our main contributions can be summarized as follows:
- We formalize the learning task of finding an effective, cost-efficient heuristic schedule on a training dataset as a Mixed Integer Quadratic Program;
- We propose an efficient heuristic for solving the training (scheduling) problem and a scalable data collection strategy;
- We perform extensive computational experiments on two classes of challenging instances and demonstrate the benefits of our approach.
Obtaining a Heuristic Schedule
We consider the following practically relevant setting. We are given a set of heuristics $\mathcal{H}$ and a homogeneous set of training instances $\mathcal{X}$ from the same problem class we are interested to solve in practice. In a data collection phase, we are allowed to execute the B&B algorithm on the training instances, observing how each heuristic performs at each node of each search tree. At a high level, our goal is then to leverage this data to obtain a schedule of heuristics that minimizes a primal performance metric.
A heuristic schedule controls two important aspects: The order in which a set of applicable heuristics $\mathcal{H}$ is executed and the maximal duration of each heuristic run. To find primal solutions, the solver executes a heuristic loop that iterates over the heuristics in decreasing priority. The loop is terminated if a heuristic finds a new incumbent solution. As such, an ordering that prioritizes effective heuristics can lead to time savings without sacrificing primal performance. Furthermore, solvers use working limits to control the computational effort spent on heuristics. By allowing a heuristic to be more expensive, i.e., increase the overall running time, we also increase the likelihood of finding an integer feasible solution. Hence, a heuristic schedule is defined as follows. For a heuristic $h \in $ $\mathcal{H}$, let $\tau \in \mathbb{R}_{>0}$ denote $h$’s time budget. Then, we are interested in finding a schedule $S$ defined by
\[S := \langle (h_1, \tau_1), \dots, (h_k, \tau_k) \rangle, h_i \in \mathcal{H}.\]We also refer to $\tau_i$ as the maximal number of iterations that is allocated to a $h_i$ in schedule $S$.
Furthermore, let us denote by $\mathcal{N}_{\mathcal{X}}$ the collection of search tree nodes that appear when solving the instances in $\mathcal{X}$ with B&B. Recall that our objective is to optimize the use of primal heuristics such that we find feasible solutions fast. To achieve this, we learn from the data and construct a schedule $S$ that finds feasible solutions for a large fraction of the nodes in $\mathcal{N}_X$, while also minimizing the number of iterations spent by schedule $S$. Hence, the heuristic scheduling problem we consider is given by
\[\begin{equation} \tag{$P_{\mathcal{S}}$} \underset{S \in \mathcal{S}}{\text{min}} \sum_{N \in \mathcal{N}_{\mathcal{X}}} T(S,N) \;\text{ s.t. }\; |\mathcal{N}_S| \geq \alpha |\mathcal{N}_{\mathcal{X}}|. \end{equation}\]Here $T(S,N)$ denotes the number of iterations schedule $S$ needs to solve node $N$ and $N_S$ is the set of nodes at which schedule $S$ is successful in finding a solution. The parameter $\alpha \in [0,1]$ denotes a minimum fraction of nodes at which we want the schedule to find a solution. Problem ($P_{\mathcal{S}}$) can be formulated as a Mixed-Integer Quadratic Program (MIQP).
To find such a schedule, we need to know the number of iteration it takes heuristic $h$ to solve node $N$ for all heuristics in $\mathcal{H}$ and nodes $\mathcal{N}_{\mathcal{X}}$. Hence, when collecting data for the instances in the training set $\mathcal{X}$, we track for every B&B node $N$ at which a heuristic $h$ was called, the number of iterations $\tau^h_N$ it took $h$ to find a feasible solution. We propose an efficient data collection framework that uses a specially crafted version of a MIP solver for collecting multiple reward signals for the execution of multiple heuristics per single MIP evaluation during the training phase. As a result, we obtain a large amount of data points that scales with the running time of the MIP solves.
Unfortunately, the problem ($P_{\mathcal{S}}$) is $\mathcal{NP}$-hard and too expensive to solve in practice, so we direct our attention towards designing an efficient heuristic algorithm. The approach we propose follows a greedy tactic and the basic idea can be summarized as follows: A schedule $G$ is built by successively adding the action $(h,\tau)$ to $G$ that maximizes the ratio of the marginal increase in the number of instances solved to the cost (w.r.t. a cost fuction $c$) of including $(h,\tau)$. In other words, we start with an empty schedule $G_0 = \langle \rangle$ and successively add actions more detailed description as well as the pseudo-code can be found in our paper.
\[\begin{equation*} \begin{aligned} g_j = \underset{(h,\tau)}{\text{argmax}} \frac{|\{ N \in \mathcal{N}_{\mathcal{X}}\setminus \mathcal{N}_{\mathcal{G}_{j-1}} \mid \tau_N^h \leq \tau\}|}{c_{j-1}(h,\tau)}, \end{aligned} \end{equation*}\]until either all nodes in $\mathcal{N}_{\mathcal{X}}$ are solved by $G_j$ or all heuristics are already contained in the schedule. A more detailed description as well as the pseudo-code can be found in our paper. Our code can be found here.
Sneak Peak at the Results
A comprehensive experimental evaluation shows that our approach consistently learns heuristic schedules with better primal performance than the default settings of the state-of-the-art academic MIP solver SCIP. For instance, we are able to reduce the average primal integral by up to 49% on two classes of challenging instances – namely the Generalized Independent Set Problem (GISP) [2] and Fixed-Charge Multicommodity Network Flow Problem (FCMNF) [3]. A brief comparison of the average primal integral over time is shown in the following figure.
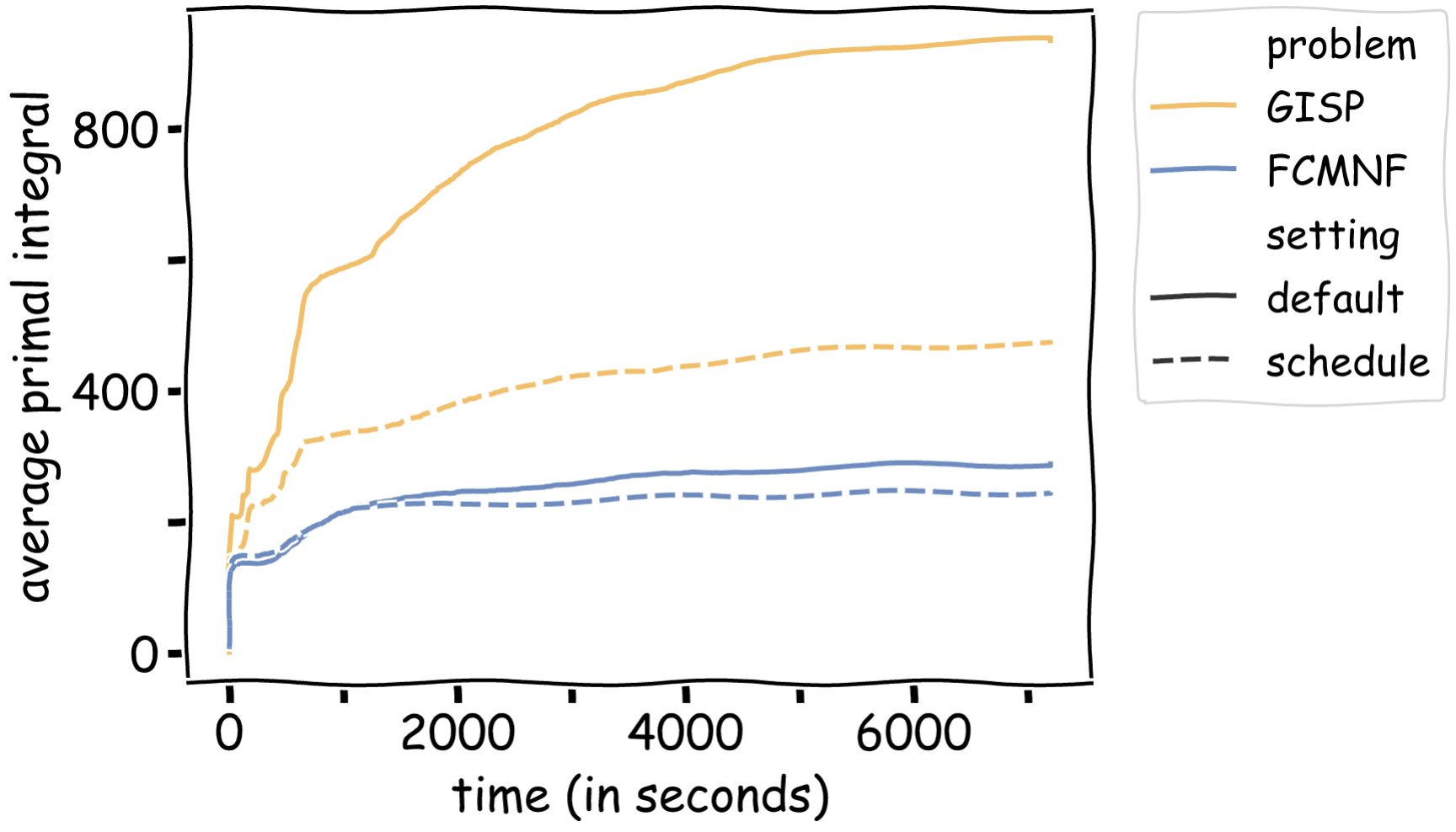
The average primal integral is not the only performance metric for which we observed a significant improvement. On average, the instances solved with the schedule terminated with a smaller primal-dual gap, a better primal bound (for instances that hit the time limit) and overall found more solutions during the solving process.
References
[1] Timo Berthold. Measuring the impact of primal heuristics. Operations Research Letters 41.6 (2013): 611-614. [pdf]
[2] Marco Colombi, Renata Mansini, Martin Savelsbergh. The generalized independent set problem: Polyhedral analysis and solution approaches. European Journal of Operational Research 260.1 (2017): 41-55. [pdf]
[3] Lluís-Miquel Munguía, Shabbir Ahmed, David A. Bader, George L. Nemhauser, Vikas Goel, Yufen Shao. A parallel local search framework for the Fixed-Charge Multicommodity Network Flow problem. Computers & Operation Research 77 (2017): 44-57. [pdf]
Comments