The Agentic Researcher
TL;DR: This is a summary of our recent paper The Agentic Researcher: A Practical Guide to AI-Assisted Research in Mathematics and Machine Learning by Max Zimmer, Nico Pelleriti, Christophe Roux, and Sebastian Pokutta augmented with some personal perspectives and thoughts. The main point is not that AI can now “do research” in some vague science-fiction sense. The more useful point is that, with the right workflow, general CLI coding agents can already act like research associates: they can write proofs, formulate conjectures, implement ideas, run experiments, document failures, verify intermediate claims, and keep going for hours, while the researcher remains responsible for idea generation, creativity, direction, judgment, and final verification.
Introduction
Over the last year, the discussion around AI and research has become increasingly confused. We jump between olympiad medals, benchmark wins, flashy demos, and vague claims about autonomous science and “fully-automatic end-to-end research pipelines”. Many of these flashy claims do not hold up or do not generalize; and most importantly in my book this should also not be the point. The useful question for me is a different, more practical one:
If I am an actual researcher in, say, Math or ML, how can I use these systems in my daily work?
That is the question our paper tries to (partially) answer and in some sense it is an amalgamation of research efforts, best practices, and approaches that we have collected over the last roughly 1.5 years in the MATH+ project “Agentic AI in Mathematics”, although our learnings go significantly beyond mathematics.
The backdrop is, of course, quite remarkable with several high-profile achievements. Systems such as AlphaGeometry [AG], AlphaProof [AP], AlphaEvolve [AE], and more recently Aletheia [ALET] have pushed AI much further into mathematical reasoning and discovery than most people expected only a short while ago. The picture is broader than just these headline systems and includes AlphaGeometry2 [AG2], Aristotle [ARI], Mathematical Exploration and Discovery at Scale [MEDS], and the autonomous Aletheia follow-up on First Proof [ALET2]. On the benchmark side, there is now a growing ecosystem around research-level evaluation, e.g., First Proof [FP], FrontierMath [FM], and RealMath [RM]. At the same time, there is a parallel line of work around agentic experimentation and end-to-end “scientific” pipelines, such as The AI Scientist [AIS], ScienceAgentBench [SAB], Karpathy’s autoresearch [AR], and, in a somewhat different flavor, FunSearch [FS]. There is also now a small but growing literature on mathematicians and researchers using these systems in practice, e.g., Avigad [AV], Henkel [H], Dobriban [D], Liu et al. [LCP], and Carbone [C].
All of this is very interesting and inspiring, but the main question remains: How do we unlock “AI for research” in a practical way that supports day-to-day research activities? Most researchers do not want to build a giant bespoke1 discovery system from scratch. They want to know which tools are already useful today, where the actual leverage is, and which guardrails are needed so that the system does not quietly produce nonsense while sounding very confident. Moreover, they need support in open-ended research endeavors and not merely round-trip IMO problems, which have “one correct answer”. In some sense, the core claim of our paper is simple:
NB. I would like to stress one point here, as this is often confused. Neither do we claim nor aim for fully-automatic end-to-end research. On the contrary, we look at the use of AI as augmentation. Not oracle. Not autopilot. Not replacement. A research associate. Moreover, we are interested in AI systems for open-ended research questions rather than benchmark problems.
Refutation and verification
Our approach operationalizes (or better: tries to operationalize) a very old and, in my view, still very fundamental scientific principle: most attempts are wrong. That sounds banal, but AI systems used “straight-up” have the tendency to produce enough wrong things fast enough (i.e., the failure rate went down but the speed went up, so that the inter-arrival rate of blow-ups is roughly constant) that it erodes trust in the system. Moreover, there is a total lack of calibration: the AI typically does not know where it is unsure and where it could be wrong; in an optimal world the system would attach a well-calibrated probability of correctness to its output, but that seems out of reach, at least at the moment. This has real consequences for how one should use these systems. If an agent only writes polished explanations, tidy derivations, or plausible-looking code, then it is mostly helping you produce surface area: it looks good but has little substance. What actually matters in research is the ability to rule out bad ideas, broken proof strategies, buggy implementations, and misleading empirical wins quickly and cleanly: we need conjectures, refutation, and falsifiability, which brings us straight to Popper (see Stanford Encyclopedia of Philosophy entry on Karl Popper [POP]) and his philosophy (see Britannica’s discussion of eliminativism and falsification [FAL]). No worries, we will skip the philosophy discourse today. The key point is that it is not indulgence but naturally induces a working research habit underneath it: propose something, expose it to failure, and only keep it around provisionally if it survives. Now what survives might still be wrong, but much less so, and that is then where the Human-AI Co-Creativity [HP] takes place.
In practice, this means the agent needs tools for both refutation and verification. That can be a numerical sanity check, a brute-force search for a counterexample, a symbolic derivation, a randomized stress test, a Julia script, a Python script, or some small utility wired into a simulator, etc. Today this is more straightforward than ever: tons of very strong, localized package managers, such as bun, npm, uv, cargo, Pkg, that align perfectly with agents in CLIs being able to write small refutation and verification scripts against their own reasoning to harden it. Once the agent can actually run those checks, we are no longer asking it merely to talk about a hypothesis. We are asking it to try to break it.
This makes a fundamental difference and the consistency and correctness of the output changes dramatically. Verification catches arithmetic mistakes, implementation bugs, and overclaimed results. Refutation-oriented checks kill wrong turns early and force the system to document why an idea failed. In my experience, this is exactly where these agents start becoming useful for real research: not when they sound convincing, but when they can help eliminate what is false.
Five levels of AI integration
To put things into perspective, inspired by the taxonomy in [HP], we distinguish five levels of AI integration, starting at zero, “research without AI”, which is still the default mode, probably one of the most robust modes out there, and the all-important baseline.
| Level | Name | What it looks like |
|---|---|---|
| 0 | Classical | Normal research without AI: LaTeX, code, math software, papers, whiteboards, coffee, despair, and hopefully eventually progress. |
| 1 | Consultant | The chatbot regime: explanations, brainstorming, literature pointers, debugging, and other targeted questions. Useful, but episodic and reactive. |
| 2 | Typist | The AI writes code or text for you, but does not really execute or iterate. Think completion, drafting, or small prompt-based generation. |
| 3 | Collaborator | CLI coding agents such as Claude Code [CC], Codex CLI [CX], OpenCode [OC], or Gemini CLI [GC] can read files, edit them, run code, inspect outputs, and iterate inside a project context. At this level, the human says what to do and the agent handles much of how to do it. |
| 4 | Research associate | The researcher provides the problem, context, constraints, codebase, prior attempts, and evaluation criteria. The agent then runs an actual research loop: explore -> plan -> implement -> evaluate -> analyze -> record -> commit -> iterate, with the human stepping in periodically for steering, review, and correction. |
The key difference from Level 3 is that the agent does not stop after every experiment to ask what to do next. It continues autonomously within a carefully bounded workflow, and the human intervenes periodically for steering, review, and correction. This is exactly the boundary point where “AI as tool” becomes “AI as research associate”.

Figure 1. A useful way to think about the research-associate setup: the agent gets a concrete research question, the relevant tools and data, and the prior work or domain knowledge needed to operate in context.
The actual contribution is the workflow
While the taxonomy is useful, the important part of the paper is the actual workflow. The paper’s main claim is that one does not need a highly specialized custom-built system to get meaningful agentic research behavior. Instead, one can take strong existing CLI agents and wrap them in a disciplined environment:
- persistent instructions
- sandboxed execution
- a structured report
- a live
TODO.md - Git-based experiment tracking
- a set of explicit methodological rules
The result is a system that is much less magical than the hype suggests, but also much more useful in practice. It just works. And it is highly customizable to the research needs of the individual researcher. It is your tool.
The workflow in the paper runs inside a sandboxed container, keeps all progress in inspectable artifacts such as report.tex (which I, for example, often have open simultaneously in VS Code so I can regularly compile the PDF and preview it) and TODO.md, and can scale from a laptop to multi-node Slurm experiments. The longest autonomous session reported in the paper ran for more than 20 hours; we have much longer sessions with repeated calls to downstream tools for subproblems. That sounds dramatic, but the important part is not the wall-clock number. The important part is that the agent keeps a disciplined experimental loop alive over long horizons without silently discarding context, changing metrics, or forgetting what it already tried. I would go one step further: this kind of “external memory” is one of the main reasons long sessions are usable at all. In other words: the secret sauce is not some mystical “agent architecture”. It is mostly methodology (e.g., refutation and verification) and workflow (e.g., persistency); granted, for high-profile applications we do rely on SOTA LLMs (current favorites being Claude Opus 4.6 and GPT-5.4).
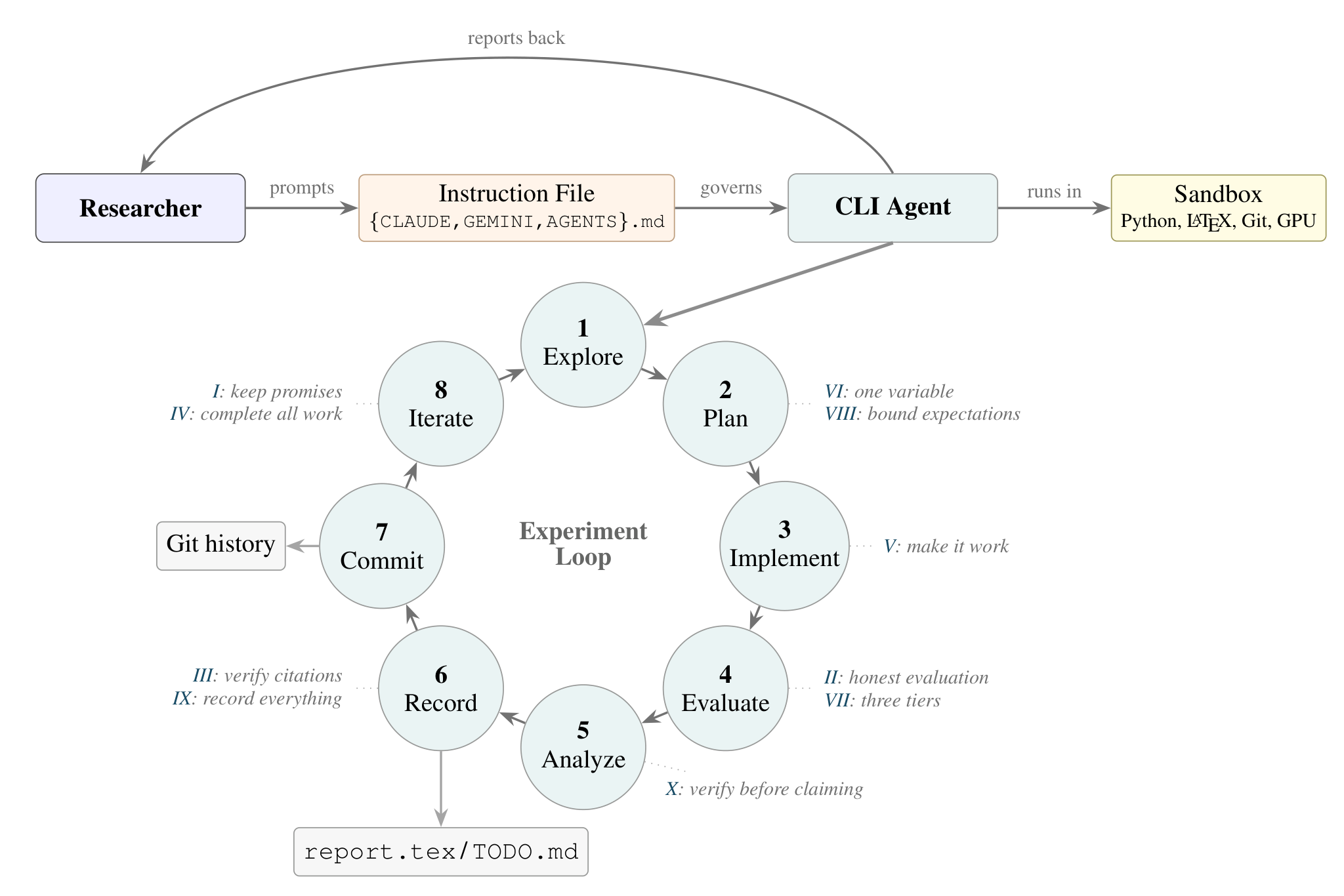
Figure 2. The workflow view from the paper: persistent instructions, a CLI agent running inside a sandbox, and an explicit experiment loop with reporting, verification, and Git-based memory.
The commandments
We have encoded the “rules” that guide the systems’ behavior as “ten commandments”, which sounds a bit theatrical but follows the language escalation paradigm to harden rule-following; yes, it does make a difference. The underlying rule-of-thumb is: if a behavior matters, make it explicit. Do not rely on vague hopes like “the model will probably know what I mean”. I will not list all ten in full here and I grouped them by the overarching goal. In the following the term experiment is used broadly, to mean one agentic-loop iteration, e.g., proof attempt, one numerical experiment, one design attempt, etc.
1. Integrity and trust.
The first group is basic research hygiene:
- do not promise work and then quietly skip it
- do not change the evaluation because the original setup looks inconvenient
- do not invent bibliography
This sounds trivial until you actually let these systems run for hours. Then it stops sounding trivial very quickly.
2. Autonomy and efficiency.
The second group is about making the agent actually useful rather than merely interactive:
- finish autonomous work before reporting back
- treat crashes as bugs unless proven otherwise
This addresses one of the most common failure modes: the agent stops too early, asks for permission too often, or mistakes implementation bugs for failed research ideas. “Dangerously skipping all permissions” does not solve your problem here; you need to “unleash” the agent.
3. Scientific rigor.
The third group is the most important “research-specific” one:
- change one variable per experiment
- evaluate in tiers
- bound the best-case improvement before celebrating a heuristic
The “one variable per experiment” rule is particularly powerful. It sounds almost embarrassingly obvious, but it prevents a huge amount of pseudo-progress and conflation of factors. If two things change and the metric improves, you often do not know what actually helped.
The staged evaluation rule is equally important. A fast sanity check is for catching bugs, not for drawing conclusions. This is exactly the kind of thing researchers understand intuitively and agents do not unless told very explicitly.
4. Documentation and reproducibility.
The last group is what makes the whole system robust over long sessions:
- record everything
- verify before claiming
This means that failed experiments go into the report as well, not only the good-looking ones. It also means that a claim is not “explained” into existence but should be stress-tested, checked numerically, or challenged through a verification script whenever possible. Everything not fully “verified” is considered “unverified” and “unproven”.
The three meta-principles behind this go back to our refutation discussion at the beginning:
- explicit over implicit
- falsifiable over aspirational
- failure-driven over theory-driven
“Be rigorous” is not a usable instruction. “Change exactly one variable per experiment” is. Similarly, “failure-driven over theory-driven” ensures that things are constantly stress-tested and hardened, rather than endless proof-attempts over pages where the mistake is in the assumptions or right at the beginning.
Three sample case studies
The paper contains six case studies across ML and mathematics. I will only discuss three here, because they already show most of the pattern; for the others, check the paper. All figures below marked with [sic] are verbatim, unaltered output from the agent.
1. Optimizer exploration for LLM pretraining
The first case study starts from a concrete and very ML-style question. AdamW uses two extra buffers per parameter, while Muon only uses one. The natural question is whether the spare memory budget can be used to make Muon better.
This is exactly the kind of problem where our agentic workflow shines: there is a nontrivial design space, the experiments are expensive, and the researcher mostly wants disciplined exploration rather than one-shot “creativity”. For this case study, the agent ran more than 40 experiments, changing one thing at a time, and discovered two largely independent improvements:
- a normalization before orthogonalization
- weight decay for Muon’s matrix parameters
The combined result is about a 5% improvement in validation perplexity over Muon and about 8% over AdamW at the same memory budget, i.e., basically for free. Even more interestingly, the agent also found a nearly matching zero-overhead variant. This application demonstrates what Level 4 autonomy looks like in a compute-heavy setting: multiple GPUs, long runs, careful ablations, literature checks, and a report that keeps all of this coherent over a session lasting more than 20 hours.
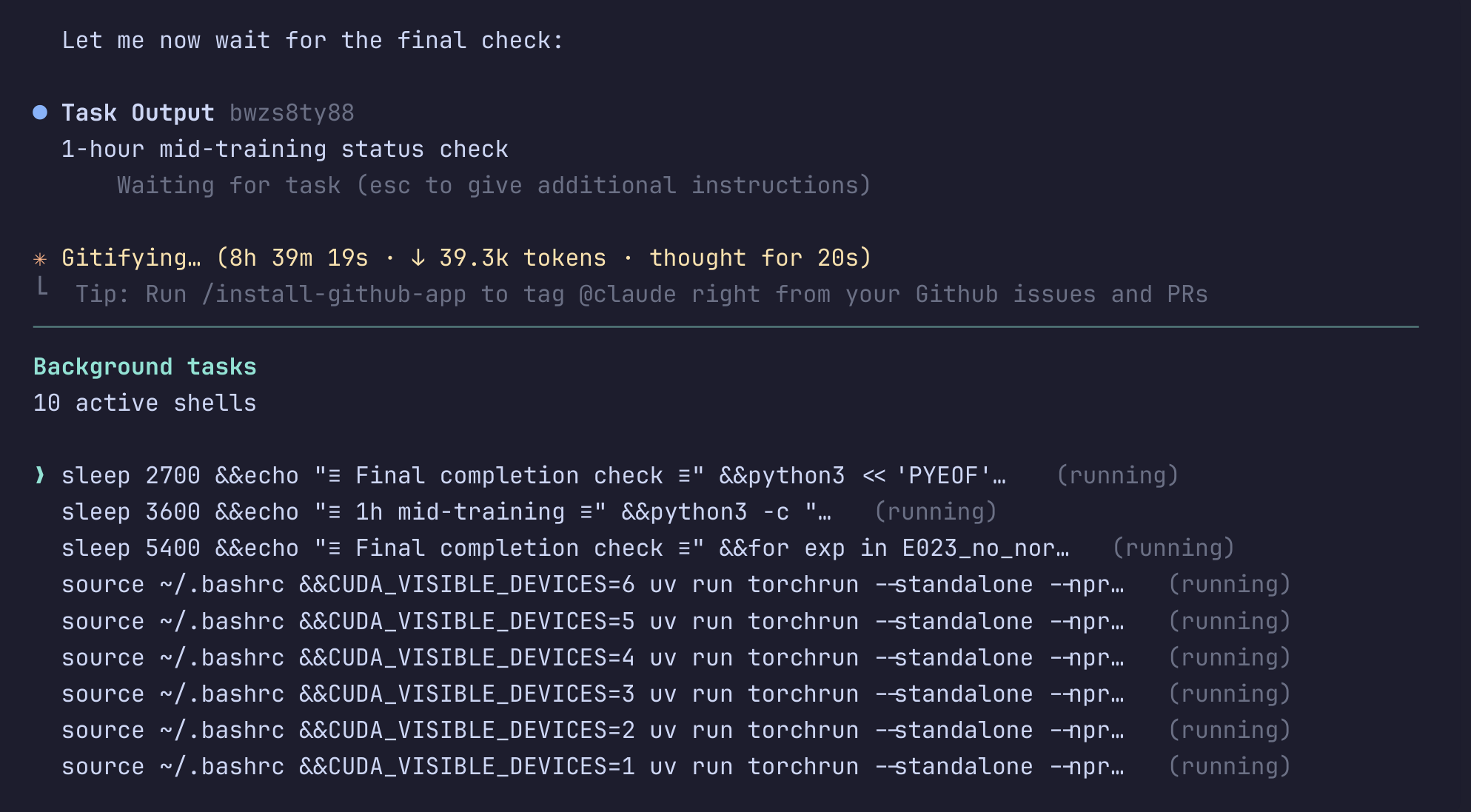
Figure 3. A terminal view from a long-running session. Multiple training jobs, timed checks, and verification tasks stay alive in parallel while the agent keeps an inspectable record of what is running.

Figure 4. [sic] Final validation perplexity for the optimizer exploration case study. Lower is better; the best learned variant improves over both Muon and AdamW at the same memory budget.
2. Weight reconstruction in LLM pruning
The second case study, while still in the LLM space, highlights a different aspect that we encountered quite regularly: serendipity. The original task was to fix a broken pruning-mask idea. The agent eventually concluded that the original approach was mathematically flawed. But instead of just discarding the project and moving on, it analyzed why the approach failed. During that analysis, it observed a strong imbalance in post-layer activation distortion after pruning and proposed a very simple reconstruction step to compensate for it.
The resulting method is almost comically lightweight:
- about 10 lines of code
- less than 1% computational overhead
- no hyperparameter tuning
Yet it reduces perplexity by 18–50% across multiple model scales, architectures, and pruning methods, and captures about 92% of the gain of a least-squares oracle reconstruction.


Figure 5. [sic] The pruning reconstruction idea transfers across model scales. Left: relative improvement versus model size. Right: absolute perplexity comparison against the baseline.
3. Frank-Wolfe lower bounds on uniformly convex sets
The third case study comes from optimization, more precisely (as you might have guessed) from the Frank-Wolfe and conditional gradients domain. The problem is was an open lower-bound question for vanilla Frank-Wolfe on uniformly convex sets. For $p$-uniformly convex sets, an upper bound of $\mathcal{O}(1/T^{p/(p-1)})$ was known due to [KDP21], but no matching lower bound was available in the relevant regime; this became in particular striking after the recent lower bounds for strongly convex sets (see [HDZRSP26] and [GL26]).
The agent first tried to generalize an existing high-dimensional lower-bound construction and failed. Importantly, this failure was documented rather than hidden. It then pivoted to a more direct dynamical analysis of the Frank-Wolfe iterates on $\ell_p$-balls, used numerical exploration to identify the right pattern, and eventually assembled a proof showing a lower bound of
\[\Omega(1/T^{p/(p-1)})\]for $p \geq 3$, matching the known upper bound in that regime. This particular application touched on each step of the research loop for mathematics:
- try a proof strategy
- fail
- document the obstruction
- switch to computation-guided exploration
- identify structure
- derive the proof
- verify numerically along the way
- verify once more symbolically

Figure 6. [sic] Log-log convergence for the Frank-Wolfe lower-bound case study. The empirical behavior matches the rate suggested by the analysis.
There are three more case studies.
I am not going through the remaining three in detail here, but they are also worth reading:
- GPTQ column ordering in LLM quantization
- multi-variable dual tightening for Boscia and mixed-integer convex optimization
- extremal search for maximal real solutions in $K_7$ power networks
They essentially make the same basic point: the agent is most useful when it can combine implementation, experimentation, proof attempts, verification, and structured reporting inside a single inspectable loop.
Limitations: What this does not solve
Verification remains the central problem. Natural-language proofs still require human inspection; we think of this more as a feature than a bug. Code is easier to check (syntax, types, compile checks, unit tests, integration tests, etc.), but subtle bugs remain dangerous. Citations remain a known weak point; tools such as OpenAlex can help a lot but are not a silver bullet. There are formal verification tools such as Lean 4 available, but in our experience this often does not scale (yet?!) to actual research workflows; in particular when paradigm changes are present (e.g., numerics vs. symbolics vs. computational exploration vs. writing a SAT program as proof). So yes, the researcher still owns final verification (and responsibility).
Novelty is not automatically solved. An agent can search the literature and reduce the burden, but it cannot guarantee novelty. This is especially important now that many groups are exploring similar design spaces with similar tools. The researcher still has to do the serious prior-art work.
Context remains fragile. Long sessions eventually hit context-window limits. This is why the persistent external memory in report.tex and TODO.md matters so much. Without it, the system will forget, repeat itself, or silently lose important information. Nonetheless, this does not fix all cases of context churn. Also, simply more context like Claude Opus 4.6’s 1m token window is not an immediate fix either: the context needs to be actively managed with meaningful information and simply having a larger context window also increases the risk of context pollution. As with (human) researchers, focus and concentration are key.
Cost is real, but often not the main issue. Long frontier-model sessions are not free. But in many Level 4 setups, much of the wall-clock time is actually spent waiting for code, experiments, or training runs, not generating tokens. So the real bottleneck is often compute time and workflow quality, not just API cost.
A couple of final thoughts
My overall view is quite positive. Used in the right way, these systems are already good enough to impact how research is done, potentially opening up new avenues. They are particularly strong on the wide, messy, implementation-heavy part of research: exploring various proof directions, setting up experiments, checking boundary cases, writing and revising code, keeping notes, running ablations, and simply pushing several lines of attack in parallel for much longer than a human would do manually. This is not the same as “fully autonomous science”, but it is absolutely real leverage.
At the same time, I do not believe in unbounded speedups either. Research is not one isolated task; it is a workflow. And workflows obey Amdahl’s law [AL26]. Even if the agent becomes extremely fast at some parts of the loop, the remaining serial parts still cap the total gain: choosing the problem, deciding what actually matters, judging novelty, interpreting ambiguous evidence, and performing final verification. These pieces do not go away just because code generation or argument generation got faster. So no, I do not expect 100x researcher productivity. In many realistic settings the true ceiling is much lower.
Then there is the rework problem, which in practice is at least as important. Every wrong derivation, flaky script, plausible-but-false citation, or misleading empirical win creates a tax that has to be paid later by the researcher. Local speed does not automatically turn into global speed. If the system saves you two hours and then costs you ninety minutes of checking, cleanup, and reinterpretation, the headline gain is mostly fiction. This is one reason why disciplined workflows matter so much: they reduce the rework tax before it compounds.
There is also a more subtle downside risk. If you use the agent to outsource the core thinking, you may get more text, more code, and less understanding. In that sense there is indeed a “thinking tax” if the tool is used lazily [TT26]. But if you use it to harden your own reasoning, by searching for counterexamples, stress-testing claims, implementing verification scripts, and documenting failed attempts, then the system becomes genuinely valuable. That distinction is crucial.
So my expectation is neither “AI changes nothing” nor “AI gives us fully autonomous science”. However, the realistic middle ground is already quite useful: better exploration, broader search, faster implementation, more systematic verification, and the ability to sustain open-ended research loops for longer. Even a fairly mundane 2x on the right parts of research would be enormous over the course of a few years. But to get there, we have to be honest about the downside risks as well: overtrust, cognitive atrophy, workflow bloat, and rework. The researcher remains the one who has to decide what is important and what is worth believing.
References
(for a more complete list, see our paper [ZPRP26] and the references contained therein)
Main paper.
[ZPRP26] Zimmer, M., Pelleriti, N., Roux, C., Pokutta, S.: The Agentic Researcher: A Practical Guide to AI-Assisted Research in Mathematics and Machine Learning (2026)
AI for mathematics and mathematical discovery.
[AG] Trinh, T. et al.: Solving olympiad geometry without human demonstrations (2024)
[AP] Hubert, T. et al.: Olympiad-level formal mathematical reasoning with reinforcement learning (2025)
[AG2] Chervonyi, Y. et al.: Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2 (2025)
[ARI] Achim, T. et al.: Aristotle: IMO-level Automated Theorem Proving (2025)
[AE] Novikov, A. et al.: AlphaEvolve: A coding agent for scientific and algorithmic discovery (2025)
[MEDS] Georgiev, A., Gómez-Serrano, J., Tao, T., Wagner, S.: Mathematical exploration and discovery at scale (2025)
[ALET] Feng, Y. et al.: Towards Autonomous Mathematics Research (2026)
[ALET2] Feng, Y. et al.: Aletheia tackles FirstProof autonomously (2026)
[FP] Abouzaid, M. et al.: First Proof (2026)
[FM] Glazer, D. et al.: FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI (2024)
[RM] Zhang, Y. et al.: RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics (2025)
AI-assisted mathematical research and human-AI collaboration.
[AV] Avigad, J.: Mathematicians in the age of AI (2026)
[H] Henkel, C.: The Mathematician’s Assistant: Integrating AI into Research Practice (2025)
[D] Dobriban, E.: Solving a Research Problem in Mathematical Statistics with AI Assistance (2025)
[LCP] Liu, Z. et al.: AI Mathematician as a Partner in Advancing Mathematical Discovery – A Case Study in Homogenization Theory (2025)
[C] Carbone, A.: Advancing mathematics research with generative AI (2025)
[HP] Haase, J., Pokutta, S.: Human-AI Co-Creativity: Exploring Synergies Across Levels of Creative Collaboration (2024)
Optimization and conditional gradients.
[KDP21] Kerdreux, T., d’Aspremont, A., Pokutta, S.: Projection-Free Optimization on Uniformly Convex Sets. Proceedings of AISTATS (2021)
[HDZRSP26] Halbey, J., Deza, D., Zimmer, M., Roux, C., Stellato, B., Pokutta, S.: Lower Bounds for Frank-Wolfe on Strongly Convex Sets. arXiv preprint arXiv:2602.04378 (2026)
[GL26] Grimmer, B., Liu, N.: Lower Bounds for Linear Minimization Oracle Methods Optimizing over Strongly Convex Sets. arXiv preprint arXiv:2602.22608 (2026)
Agentic workflows and evaluation.
[AIS] Lu, C. et al.: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (2024)
[SAB] Chen, X. et al.: ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery (2024)
[AR] Karpathy, A.: autoresearch
[FS] Romera-Paredes, B. et al.: Mathematical discoveries from program search with large language models (2023)
Philosophy of science.
[POP] Stanford Encyclopedia of Philosophy: Karl Popper
[FAL] Encyclopaedia Britannica: Philosophy of science - Eliminativism, Falsification, Theory
AI productivity and cognition.
[AL26] just a tourist: The 20x Ceiling: Amdahl’s Law and the Limits of AI Speedup (2026)
[TT26] just a tourist: The Thinking Tax: When AI Tools Cost More Than They Save (2026)
Tools.
[CC] Anthropic: Claude Code overview
[CX] OpenAI: Codex
[OC] Anomaly: OpenCode / The open source coding agent
[GC] Google: Gemini CLI
Footnotes
-
This is purely for internal amusement: yes I did use the word. ↩
Comments